


Kaggle竞赛Google-Football排名,来自

游戏中使用的Google研究足球环境是基于开源足球游戏足球开发的强化学习环境。因为它既具有挑战性又有趣,所以它在推出后吸引了来自国内外的热情参与。截至12月中旬,它吸引了来自世界各地的1,100多个团队,包括许多世界一流的大学和科学研究中的研究机构。团队。
什么是Google足球比赛?

Google足球是一场基于世界上最受欢迎的运动“足球”比赛的比赛。在比赛中,规则类似于普通的足球比赛,例如目标是将球踢入对手的进球和越位,黄色和红牌。具体细节上也有一些差异,例如游戏分为下半场和下半场(每个45分钟,1500步,两个团队每次启动一次),并且游戏场景完全对称(所以有无需改变左右两侧),没有替代球员,没有加班,更多的进球获胜(否则,绘制)等。
与普通足球视频游戏中的统一和受监管的NPC团队不同,Google足球比赛中参与球队中的每个球员都由一个单独的代理人控制。参与的团队需要实时选择和控制一个代理商,以及其他内置的代理。代理商的合作。因此,每个球员不仅需要观察对手的行为,而且还需要注意自己的球员的情况。这需要非常复杂的团队合作和竞争策略。
例如,当对手的球员控制球时,代理商不仅需要根据球场上的两个球员的分布位置来预测球员控制球员的下一步动作,而且还需要与球员合作以抓住控制足球的合规性。而且,由于法院的动态正在迅速变化,因此高速实时决策能力也是必要的。
朱乌(Juewu)与其他AIS合作以传球
此外,从头开始完全采用加强学习方法来培训完整的足球AI实际上很难。与在MOBA游戏中的经济,血量和经验等持续的实时学习信号不同,足球比赛的激励措施非常稀疏,只能依靠目标,而稀疏的激励措施一直是加强学习的主要问题。
实际上,正是由于足球队策略的复杂性,多样性和难度,因此AI领域的开拓者已经开始尝试根据足球研究人工智能技术。 Robocup于1992年开始,此后每年都举行机器人足球比赛,并且一直持续到今天。 Robocup的目标是在2050年之前击败人类足球世界冠军。但是,到目前为止,在机器人运动模拟和机器人团队的决策能力方面,这两种能力仍然很慢,而且离目标仍然很远。只需看看Robocup机器人掉下来的有趣视频亮点即可理解这一点。
尽管如此,进步仍然是切实的。得益于游戏领域深厚的强化学习的快速发展,AI代理在游戏的持续迭代和演变中变得越来越强大。这项冠军胜利的朱乌(Juewu)版本通过两种关键技术比其他竞争的AI团队获得了优势。

Wekick vs Saltyfish(第二名)最近的比赛记录为3:2
像大多数参与的团队一样,Juewu主要使用强化学习和自我播放来从头开始训练模型。其培训的基本架构基于“ Jiuwei”完整的体系结构迁移。基于此,针对足球任务的框架有针对性的改进,以使其能够适应11个特工足球比赛的训练环境。
为此,部署了异步分布式增强学习框架。尽管异步体系结构在训练阶段牺牲了一些实时性能,但其灵活性得到了显着提高,并且还支持在培训过程中按需调整计算资源的调整。此外,由于MOBA游戏和足球比赛任务目标的差异,该团队在功能和奖励设计方面进行了扩展和创新。这些改进,结合了关键的生成对抗模拟学习(GAIL)计划和联盟多式增强学习训练计划,最终为赢得冠军铺平了道路。
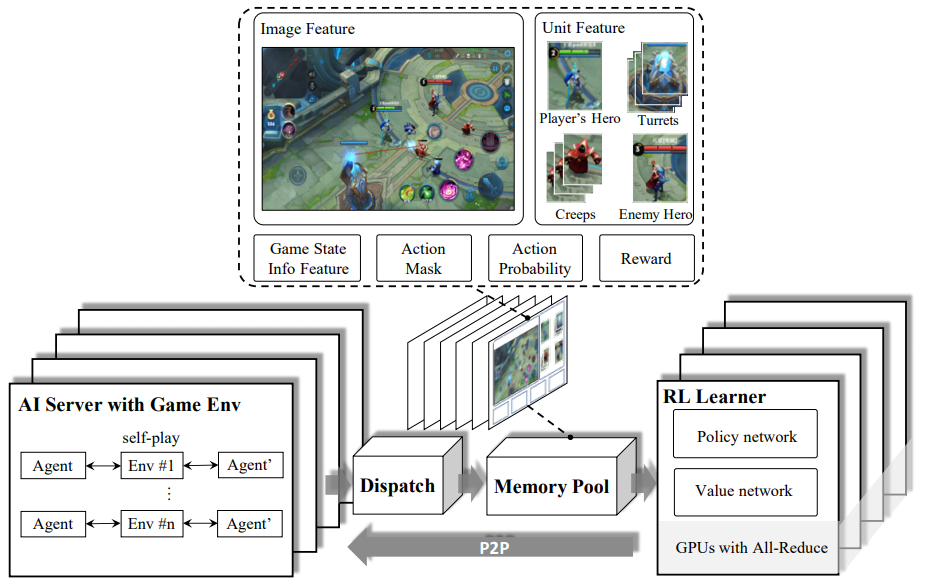
体系结构概述
具体而言,该模型由一些密集的层(每层256个维度)和一个LSTM模块(32个步骤,256个隐藏单元)组成。培训过程使用了近端策略优化(PPO)增强算法的改进版本。学习率固定为1E-4。参数更新使用ADAM优化器。该解决方案可以实现非常快速的适应和迭代,并且内存使用也更合理。
就算法而言,Juewu通常使用改进的PPO增强学习算法的版本,这与不久前发布的“ Juewu”的完整体系结构一致。简而言之,PPO算法的想法不仅可以确保在每个步骤计算更新时的成本函数尽可能小,而且还要确保与先前策略的偏差相对较小。该策略可以克服难以调试强化学习的缺点,并在实施难度,样本复杂性和调试难度之间取得适当的平衡。
在价值估计方面,采用了“ Jiuwei”全身多头价值(MHV)估计方案,也就是说,奖励将分解为多个头部,然后将使用不同的折现因子一起收集。该计划的原因是,某些事件仅与最近的行动有关,例如拦截,偏移和铲球。其他涉及一系列决定,例如目标。因此,不同事件的奖励将具有不同的权重。
在功能设计方面,研究人员将标准的115维向量扩展到包括更多功能,例如队友和对手的相对姿势(位置和方向),主动球员和足球之间的相对姿势以及可能的标记越位队友具有越位标签,红牌状态和其他特征。这些扩展为训练速度带来了30%的效率提高。
除了人工设计的回报外,朱乌(Juewu)还使用生成的对抗模拟学习(GAIL),该学习使用生成的对抗训练机制来适合国家行为的状态和行动分布,以便它可以向其他团队学习。例如,AI团队显示的“反攻击”策略给研究人员留下了深刻的印象,也就是说,球被带回→传递给守门员→守门员传给了前场。这是一个相对复杂的序列动作,很难通过手动方法来定义其奖励。但是使用Gail,Juewu可以根据重播成功学习。然后,经过盖尔训练的模型被用作进一步的自我游戏训练的固定对手,而朱乌(Juewu)的稳定性得到了进一步提高。

盖尔的优势
(Wekick的奖励设计结合了两种解决方案:奖励成型和盖尔)

通过自我增强学习获得的模型具有自然的劣势:它们可以轻松地融合到单一风格;在实际的比赛中,由于没有看到某种风格的比赛风格,单一样式模型可能会异常表现,这最终导致性能差,最终导致性能差。 。因此,为了改善该战略的多样性和鲁棒性,朱乌(Juewu)还采用了联盟多式增强学习培训计划,以完成多项式学习任务。
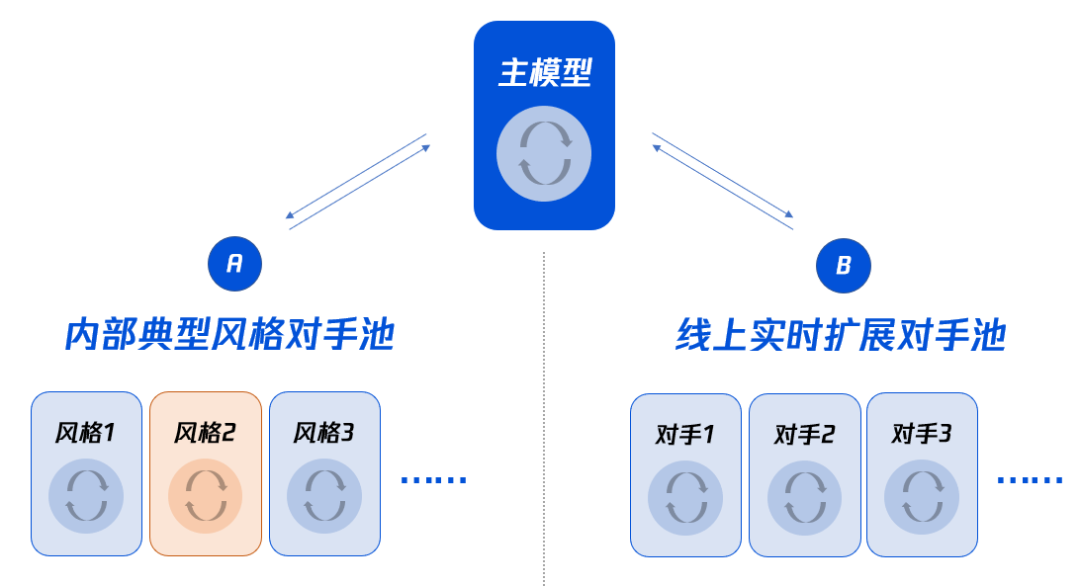
主要过程可以简单地总结为首先专门的,然后全面:
1。培训具有一定程度的竞争技能的基本模型,例如运球,传球和评分;
2。训练基于基本模型的多个风格化模型,每个模型都侧重于一种样式游戏。在样式化的模型培训过程中,将定期添加主要模型作为对手,以避免过度贴上风格和失去基本能力;
3。训练基于基本模型的主模型。除了将自己的历史模型用作对手外,主要模型还将定期添加所有风格化对手的最新模型作为对手,以确保主要模型的策略是强大的,并且可以完全适应该样式。不同的对手。
内部能力评分系统表明,加入对手池进行训练后,主要模型可以在基本模型上增加200分,比最强的风格化比赛高80分。
研究人员认为,基于联盟的多式增强学习和基于盖尔的风格学习方法是确保Wekick最终胜利的两个关键技巧。当然,基于“ Jiuwei”框架的足球任务的一些改进的设计也是必不可少的。
展望未来
Juewu的Wekick版本的整体设计基于“ Jiuwu”的完整迁移,然后为足球任务进行了一些有针对性的调整,这也证明了“ Jiuwu”的基础体系结构和方法的普遍性,这可以是可预见。预计这种类型的方法将进一步转移到将来的更多领域,例如机器人,从而创造更大的实践价值。
从Go AI“ Jiuyi”到战略决策AI“ Jiuwu”,再到当今的AI足球队“ Jiuwu” Wekick版本,深厚的强化学习智能身体已经逐步发展,逐渐发展到更复杂和更多样化的问题。这些进步中的每一个都使我们更接近通用人工智能的最终目标。
*来自Tencent AI Lab Wechat(Tencent_ailab)
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请联系本站,一经查实,本站将立刻删除。如若转载,请注明出处:http://www.ixinyuan.com/html/tiyuwenda/9521.html




